JVM 메모리 구조을 알아보고 JVM warm up을 이해하자
목표
JVM에 대해 알아보고 카카오 if 영상, JVM warm up을 이해한다.
JVM?
"Write Once, Run Anywhere(WORA)"
자바 바이트코드를 실행하는 가상머신.

자바코드는 java compiler에 의해 바이트코드(클래스 파일)로 변환되고
JVM 위에서 interprete 방식으로 실행된다.
위 그림의 backend(JVM)은 바이트코드를 어셈블리어로 바꿔야하는데 어셈블리어가 OS나 하드웨어에 종속적이다.
따라서 자바 컴파일러로 바이트코드를 만드는 부분인 compiler frontend는 OS나 하드웨어에 종속되지 않는다.
JVM 구조

Runtime Data Areas
JVM이 자바 바이트코드를 실행하기 위해 사용하는 메모리공간이다.
모든 스레드가 공유하는 Method Area, Heap Area와
각 스레드가 독립적으로 가지고 있는 Stack Area, PC Registers, Native Method Stack으로 구성되어 있다.
Method Area
클래스 로더가 클래스 파일을 읽어오면 클래스 정보를 parsing해서 Method Area에 저장한다.
Oracle은 JDK8부터 Metaspace라는 이름으로 구현했다.

위 그림은 Wooteco.class를 클래스 로더가 가져오고 Method Area에 클래스 정보를 넣어놓은 모습이다.
Crew 클래스 정보는 main 메서드를 실행하면서 동적으로 클래스 로더에 의해 기록되었다.
아래 바이트코드를 확인하면 new 연산자의 대상이 Constant Pool 7 인덱스에 저장되어 있는 것을 확인할 수 있다.
다시 7 인덱스는 8인덱스의 reference를 가지고 있고 이는 패키지와 클래스의 이름을 뜻하는 symbolic reference이다.
symbolic reference는 런타임 중에 Constant Pool Resolution으로 메모리 상에서 물리 주소로 대체된다.
Runtime Constant Pool
클래스에 사용되는 상수(Literal)들을 담은 테이블이다.
클래스 파일에 저장되어 있는 클래스 정보이고 Method Area에 기록된다.
Heap Area
런타임에 생성되는 모든 객체를 저장한다.
JVM은 객체 생성에 필요한 heap공간을 예상하기 위해서 Method Area에 저장된 클래스 정보를 사용한다.
Stack Area
스레드 별로 1개만 존재하고 메서드 호출 시마다 스택 프레임을 생성, push된다.
메서드 실행이 끝나면 프래임은 pop되어 스택에서 제거된다.
Stack Frame
스택 프레임은 3가지 구성 요소를 갖는다.
지역 변수, Operand Stack, Frame Data
지역 변수는 매개변수와 인스턴스를 가리키는 this가 포함한다.
Operand Stack은 피연산자와 중간 연산의 결과값을 저장한다.
Frame Data은 현재 메서드의 Runtime Constant Pool의 참조값과 Instruction Pointer를 갖는다.
Instruction Pointer
현재 메서드를 호출한 Stack Frame의 Instruction Pointer를 저장한다.
메서드가 정상적으로 종료되면 PC Register에 기록하여 콜백할 수 있도록 한다.
JIT compiler, Just In Time
런타임에 발생하는 정보들을 기반으로 최적화한다.
Native Method Stack
성능 향상의 목적으로, 다른 언어로 작성된 코드에 사용된다.
kakao if, JVM warm up
https://youtu.be/CQi3SS2YspY?si=ODvHL2FLvSpC-T2g
사전 지식
소스코드를 컴파일하여 기계어로 전환하는 언어는 컴파일 과정에서 최적화를 한다.
반면에 자바는 바이트코드로 컴파일한 후에 JVM에 의해 interprete 형태로 실행되기 때문에 성능 상에서 불리하다.
이를 극복하기 위해 JVM에는 JIT compiler를 사용해서 런타임 성능을 개선한다.
성능 개선에는 cache와 optimization이 있다.
optimization: 런타임 환경에 맞춰 최적화
cache: 반복되는 코드의 기계어 변환을 cache
어플리케이션 시작 직후에는 JIT compiler에 의해 저장된 cache가 없으므로 순간적인 성능 이슈를 경험할 수 있다.
이를 해결하기 위해 어플리케이션 시작과 함께 JVM warm up을 통해 의도적으로 cache를 채워넣는다.
영상에는 계정 서비스 배포시 발생한 latency 이슈 해결 과정이 나온다.
문제 분석
쿠버네티스에 의해 운영되는 계정 서비스는 롤링 업데이트를 진행하면서 응답 지연 현상을 겪는다.

tps 4천 가량의 트래픽을 받고 있고 배포 이후에 시간이 지나면 응답 지연이 해소된다는 특징이 있다.
원인 요소 검토
CPU: 평균 사용량 10% 내외 (문제 x)
Memory: 60% 이하 (문제 x)
Network bandwidth: worker node당 10~20MB 수준 (문제 x)
TPS: 배포 전후 차이가 없다. (문제 x)
외부 데이터베이스(sql, redis): 지연 확인되지 않음
Tomcat: 스레드 설정이 10~8192로 되어 있고 배포 직후 200 여개로 늘어남에 따라 시작 개수 조정이 필요하다고 판단
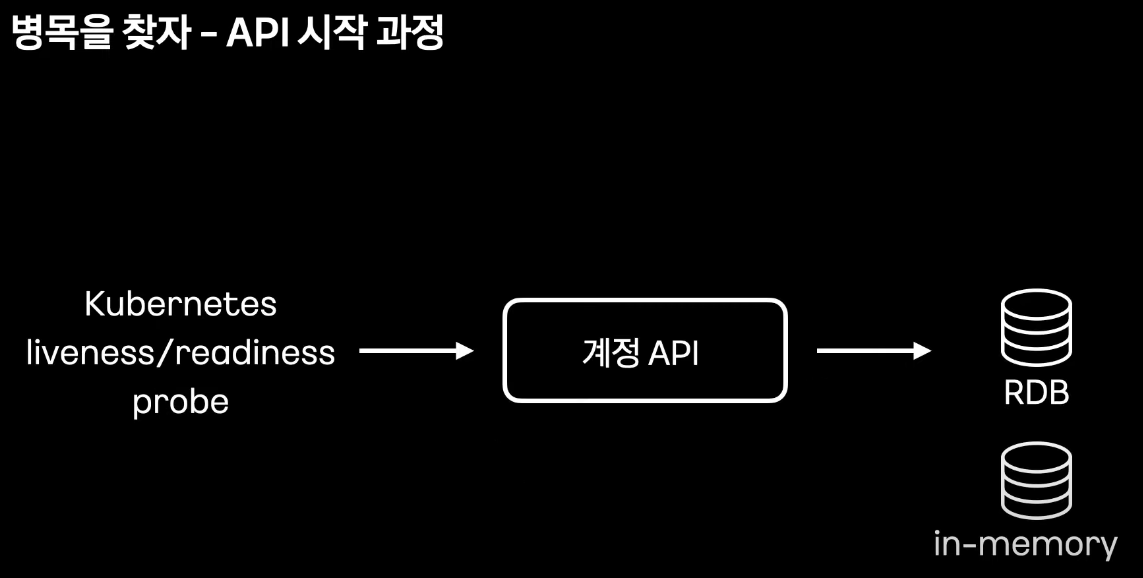
기존의 warm up 과정은 배포 직후, 쿠버네티스의 liveness와 readiness probe 요청이 오면
데이터베이스에 정해진 데이터 query를 실행하도록 되어 있다.
문제로는 실 서비스에 사용되는 api가 아니고 특정 데이터 조회 로직에 한정되어 있는 것이다.
이를 실제 트래픽과 유사한 요청을 localhost의 API 호출하도록 개선할 필요가 있다.
또한 JVM warm up 과정이 지정된 시간만큼 진행하는 것이 아니라
warm up이 완료되고 나서 readiness probe 요청에 200(OK)를 응답할 수 있도록 수정한다.

시작 스레드 개수를 늘리고 자주 사용되는 API 요청으로 warm up을 진행한다.
결과
배포 직후 응답 지연을 해결하였다.
하지만 서용자가 늘면서 TPS가 20%정도 늘어나자 다시 배포 이후에 응답 지연을 경험하게 된다.
결론적으로 warm up에 사용하는 API 요청을 실제 트래픽만큼 늘리는 것으로 해결하였다.
JIT의 깊은 이해
추가적인 조치로 문제를 해결을 이해하기 위해서는 JIT에 대한 깊은 이해가 필요하다.

JIT은 Method 단위로 바이트 코드에서 네이티브 코드로 컴파일한다.
이후 후속 최적화를 진행하기 위해서 Profiling 정보를 수집한다.
그리고 Tiered compilation(단계별 컴파일)로 코드 최적화를 진행한다.
아래 그림은 Tiered compilation이 진행되는 과정이다.

인터프리터를 통해 바이트 코드가 기계어로 번역이 되고
해당 메서드가 정해진 임계치만큼 호출되면 C1 compiler를 통해 최적화된다.
이후에 C2 compiler의 임계치만큼 호출되면 최대 최적화를 진행한다.

Tiered compilation의 레벨 단위로 표현할 수 있다.
level 0: 바이트 코드를 최적화 없이 기계어로 변경하는 단계
level 1: 간단한 c1 최적화 이후 추가적인 최적화를 진행하지 않아 프로파일링 정보를 수집하지 않는 단계
level 2: 제한된 최적화
level 3: 프로파일링 정보를 수집하여 이후 최적화를 진행
level 4: 최대 최적활르 진행하고 이번 문제를 해결하기 위해 필요한 단계

Tier3: c1의 레벨 3
Tier4: c2의 레벨 4
Invocation: 메서드의 호출 수
BackEdge: 하나의 메서드의 반복문 횟수
Compile: 메서드 호출 수와 메서드 내의 반복문 횟수를 기준으로 정해진 값

간단한 반복문 예제 코드를 이용해서 JIT log를 확인할 수 있다.
위 그림에서 compiler='c2' level='4'로 최적화되었음을 확인할 수 있다.
이는 정해진 임계치를 초과하는 메서드 호출과 반복문 횟수를 기록했다는 것을 의미한다.

warm up - N
N: 반복되는 횟수
N이 증가할수록 최적화도 비례한다는 사실을 알 수 있지만 그만큼 warm up에 필요한 시간도 늘어나는 것이기 때문에
적절한 N을 선택해야한다.

추가로 위와 같은 cache full 메세지를 받게 된다면 더 이상의 성능 향상을 기대할 수 없으므로 캐쉬 크기를 늘려줘야한다.
출처
https://rxdcxdrnine.tistory.com/23
https://youtu.be/GIsr_r8XztQ?si=Xj9TrLk3EA8d1QmM
https://youtu.be/GU254H0N93Y?si=b6OeVZQQE0enV4c8
https://youtu.be/UzaGOXKVhwU?si=0gMx3V5c6JWmOZe0
https://mindscriptstech.com/jvm-architecture/
https://deveric.tistory.com/123
'자바' 카테고리의 다른 글
| 코드 가독성 개선 with if kakao (0) | 2023.12.11 |
|---|---|
| 자바 인 액션 실전 요약 (2) Ch. 3 람다 표현식 (0) | 2023.10.19 |
| 자바 인 액션 실전 요약 (5) Ch 12. 새로운 날짜와 시간 API (1) | 2023.10.17 |
| 자바 인 액션 실전 요약 (1) Ch 1 ~ 2 자바와 동적 파라미터화 (1) | 2023.10.17 |